For Immediate Release
Date: November 28, 2022
Location: AWS re:Invent 2022, Las Vegas
Exponam announced today the limited release of the Exponam.ConnectTM Excel Add-in, an easy-to-use Excel Application which brings Delta data from Databricks (and Spark) directly to end users in Excel.
Exponam.Connect empowers business users with frictionless, no-code access to data for which they are permissioned via Delta Sharing Server(s). Users easily add data sets from company data repositories, from partner companies, and from data sellers and marketplaces.
Delta data is instantly previewable with easy controls to: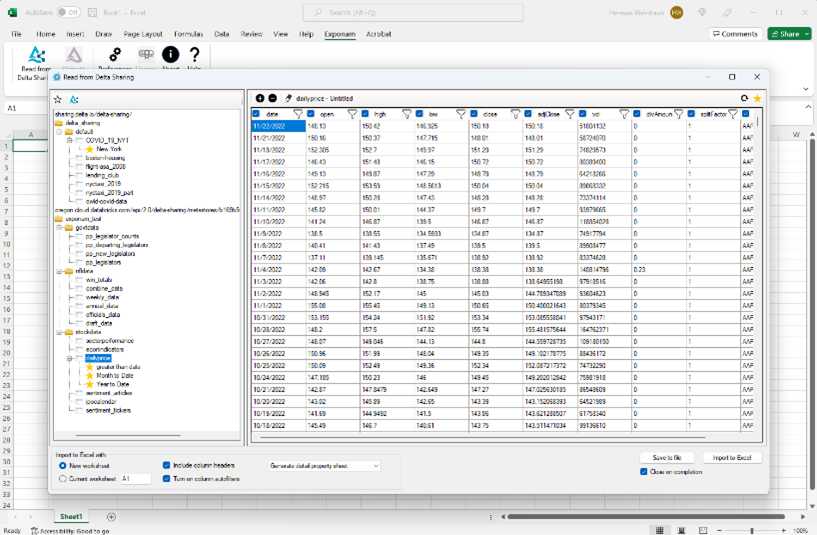
- Filter and select what data to import into Excel
- Save filters for easy repeated actions (e.g. pulling daily, weekly or monthly sales data)
- Write data straight to csv or .BIG files
Roger Dunn, Co-founder and CTO of Exponam, said: “Since 2017, Exponam’s mission has been to make modern data sets accessible to everyone. Reporting and analytics tools are great, but business users want to work with data in a spreadsheet. By partnering with Databricks, our Exponam.Connect product brings data from the world’s leading Lakehouse platform directly to non-technical business users in Excel.”
Herman Weintraub, Co-founder and CEO of Exponam, said: “For the world’s 50 million developers, cloud data and distributed compute platforms like Spark have made data more accessible and better governed than ever. But for the world’s billions of Excel users, access to data has never been more of a challenge. Exponam.Connect, opens cloud data to the world. And with our .BIGTM format, we make modern data easy to securely share, distribute, store and access.”
About Exponam
Exponam evangelizes “Empowerment through Data.” We create better ways to share, move, store, and explore data. Organizations can use Exponam.Connect and .BIG file technologies with their existing systems to make large and sensitive data easier to access, faster to share, and cheaper to store.


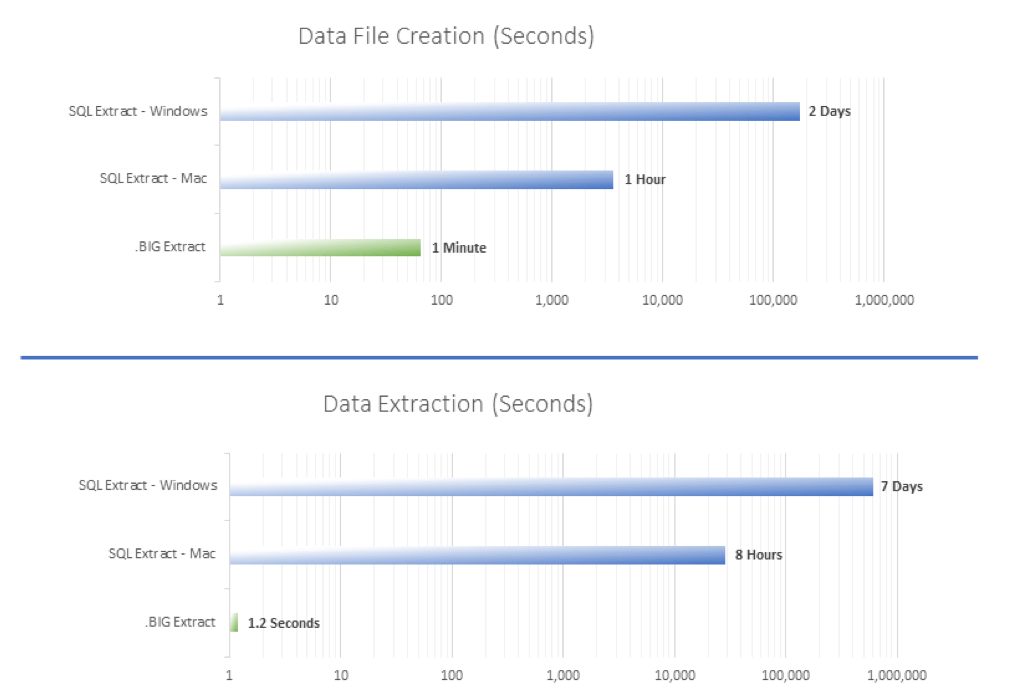 Exponam .BIG
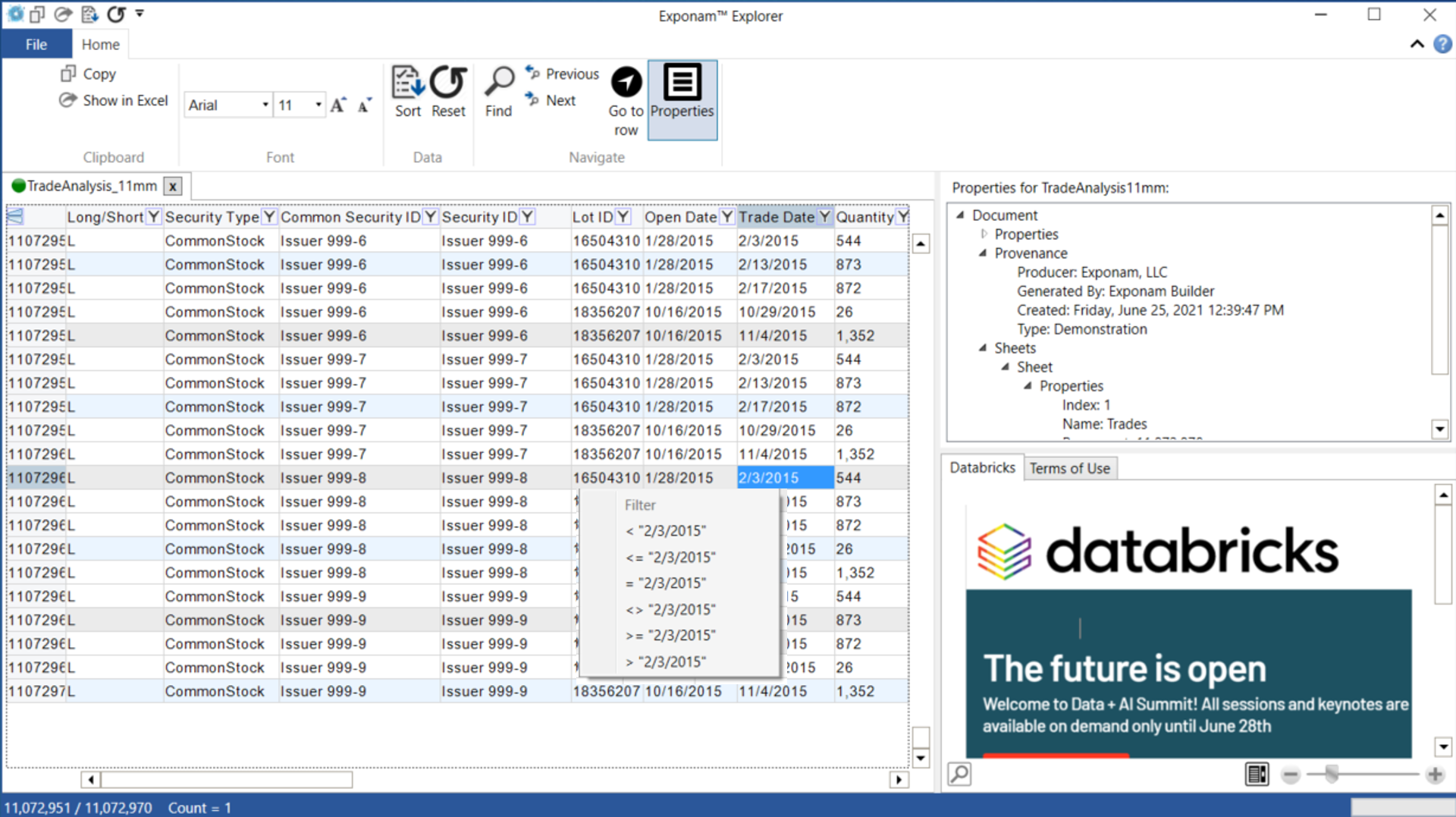
Exponam .BIG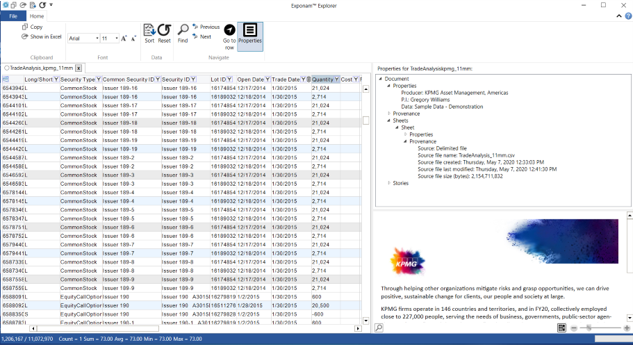 Once files have been distributed and shared, we need an easy way to access and explore data. With the Exponam Explorer, a user can instantly open, filter, sort, and find data from within a .BIG file.
Once files have been distributed and shared, we need an easy way to access and explore data. With the Exponam Explorer, a user can instantly open, filter, sort, and find data from within a .BIG file.