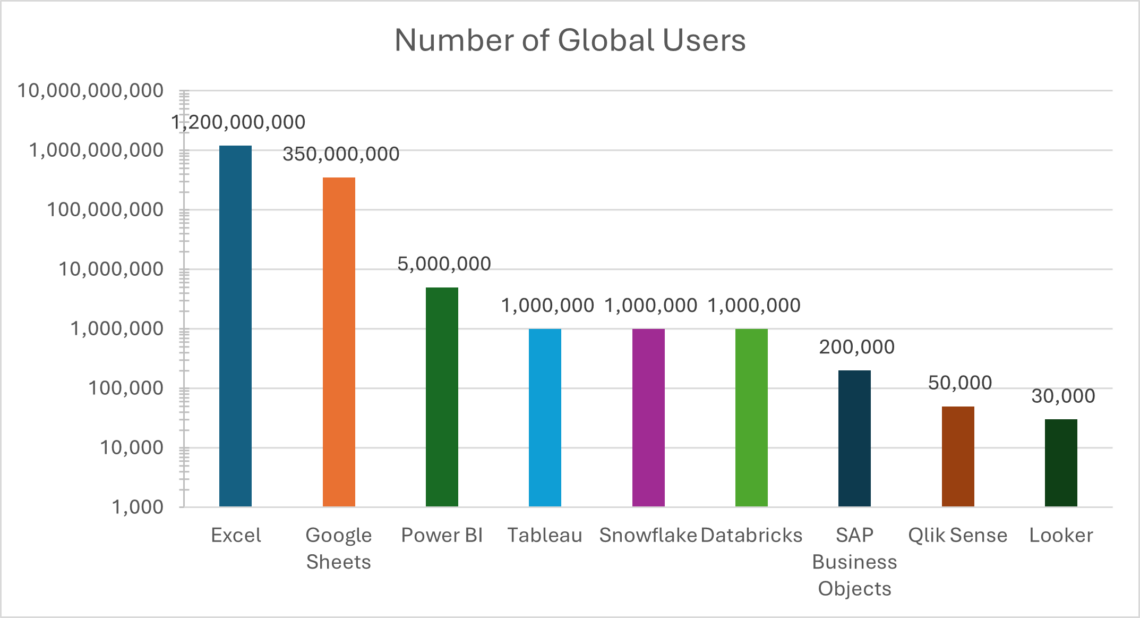
Enterprise adoption is often limited by a simple constraint: interactive compute doesn’t scale economically to every business user.
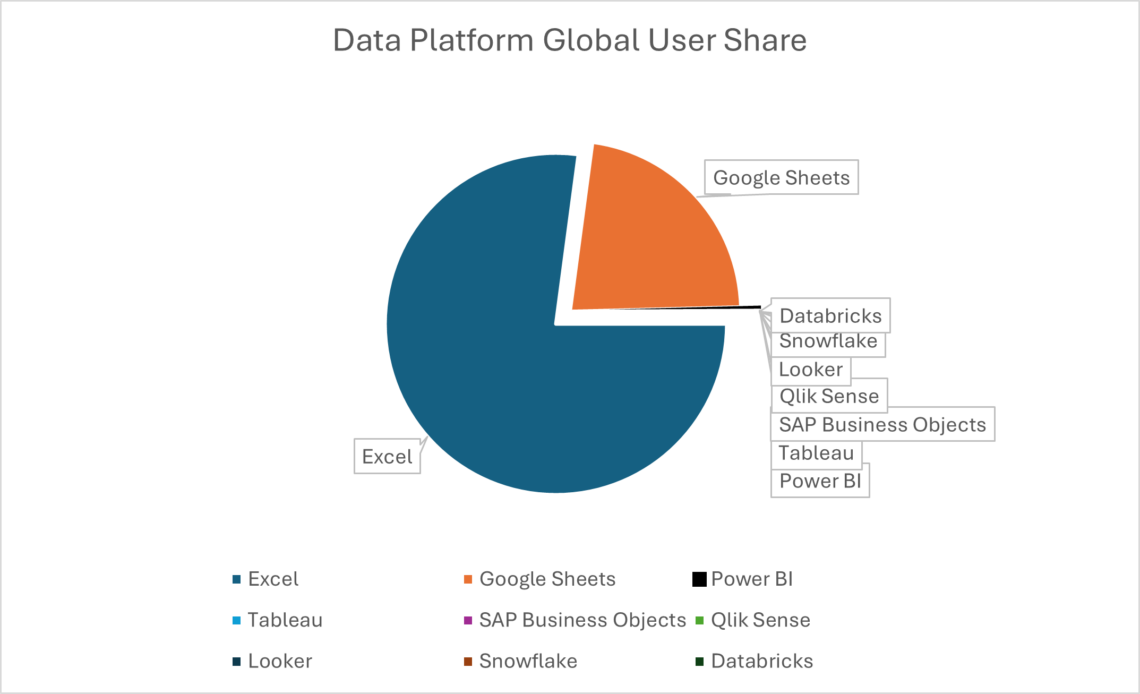
Many access patterns—whether that’s direct query through Databricks SQL, BI/semantic layers, or interactive experiences like Databricks One—can be highly effective, but they typically require compute capacity to serve user interactions. As organizations expand access from dozens of analysts to thousands of business users, that concurrency requirement can quickly become the dominant cost driver.
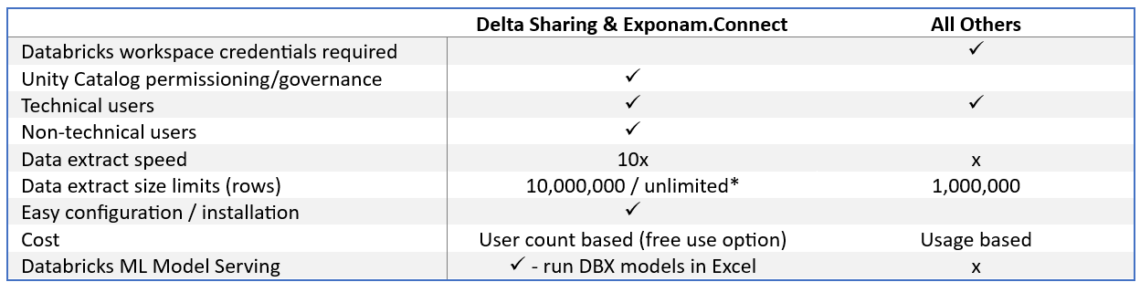
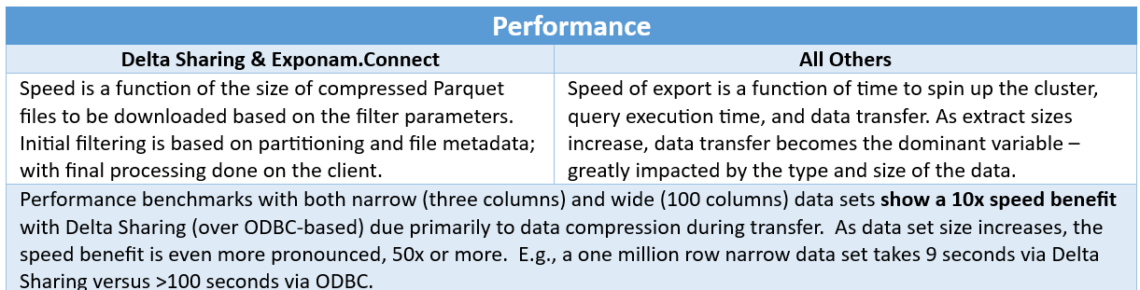
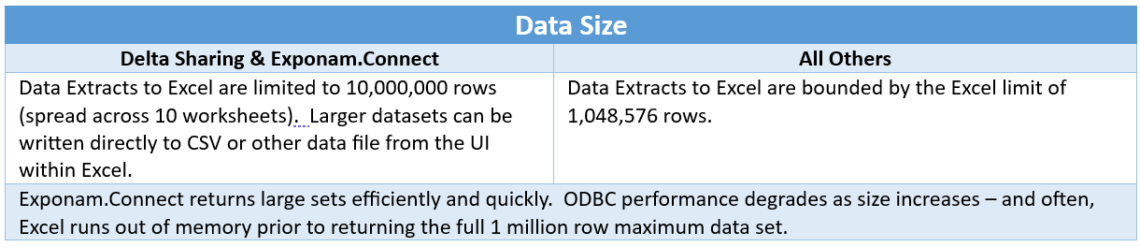
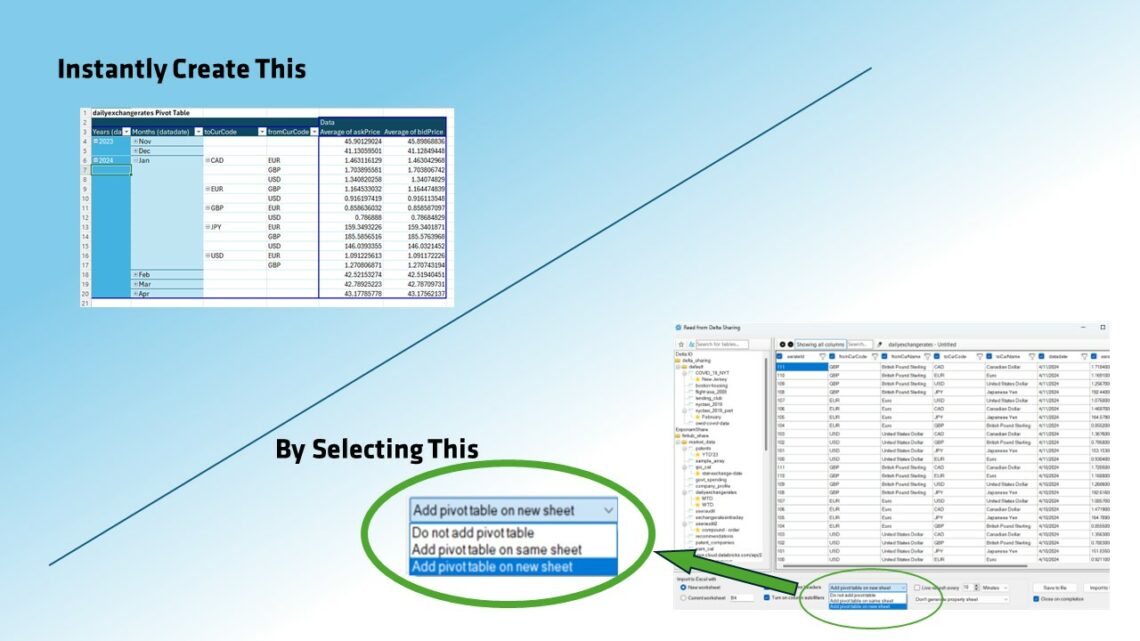
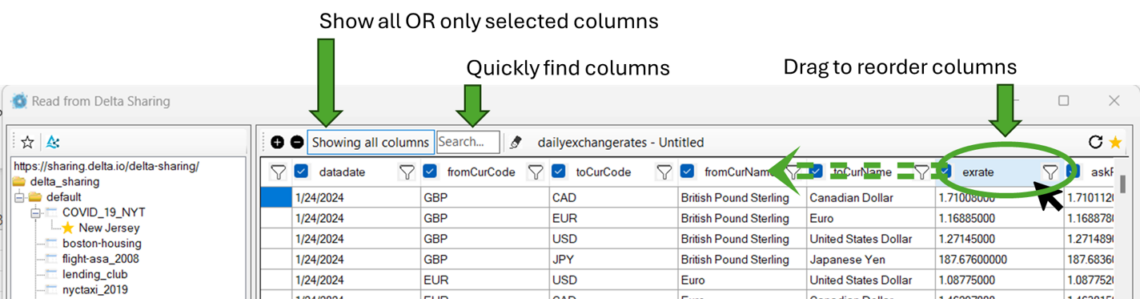
Exponam.Connect changes the equation by bringing governed Databricks data into Microsoft Excel using Delta Sharing, a protocol designed for secure data sharing across platforms. For many “read & analyze” workflows in Excel, Delta Sharing enables compute-free data access—meaning the long tail of business consumption can be served without provisioning additional interactive compute.
What this means in practice
With Exponam.Connect, enterprises can:
-
Expand access to more users in the tool they already use (Excel)
-
Reduce DBU/concurrency pressure by shifting read-heavy consumption off interactive compute
-
Maintain governance and control through shared, curated tables (Bronze/Silver/Gold)
-
Realize savings of up to ~90% in the cost of business-user access—even after accounting for licensing and potential additional curation/medallioning
The takeaway
Keep Databricks compute focused on what it’s best at—ETL, ML, streaming, and high-performance analytics—and enable broad business-user consumption through a compute-light, governed sharing model.
If you’d like, we can help you compare your current “cost per consumer” approach to a Delta Sharing + Excel model and identify which user segments and workloads are the best fit.
Learn more @ Connect