If you didn’t get to Roger Dunn’s Session at DAIS 2023 on Delta Sharing, watch the recording now.
All the hints and tricks you need to know for developing an application against the Delta Sharing REST API.
If you didn’t get to Roger Dunn’s Session at DAIS 2023 on Delta Sharing, watch the recording now.
All the hints and tricks you need to know for developing an application against the Delta Sharing REST API.

Intra-company. Inter-company. For analysis. For distribution and sale. For teams working from home. For partners, vendors, regulators. To the cloud. From the cloud.
Downloading, moving, and uploading data is slow. Firms address inefficient data movement in two ways:
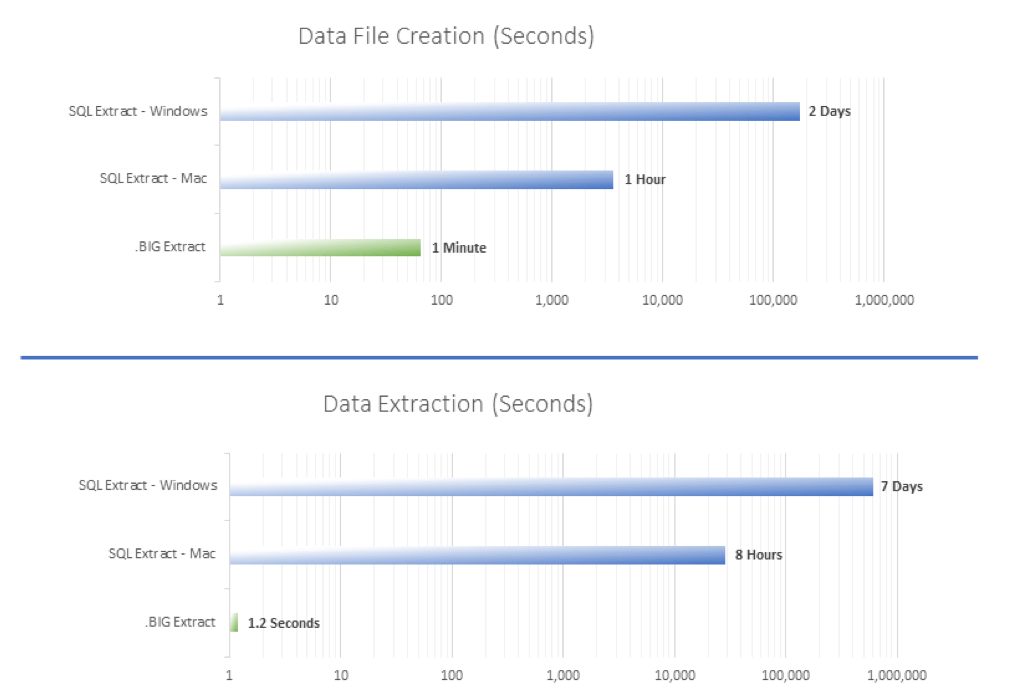
Unsatisfied with current solutions to speed data sharing and distribution, we sought a new approach. Rather than addressing the issue of time to move a single bit of data, we focused on the data itself. What could we do to decrease the size of the package, and make it more efficient for extract and import?
Today, data is transferred in different formats – csv, json, xml – but these formats all suffer the same fundamental flaws of being large and inefficient for extract and import. These formats have been used for generations – from a time when data sets were much smaller. From a time when a few million rows was a tremendous amount of data.
 Exponam .BIG
Exponam .BIGAt Exponam, we have created a new data file type – tailor made for today’s data sets. Our data file, a .BIG file, is highly compressed and is optimized for efficient extract and import. It can be used to transport, share, and explore hundreds of millions of rows quickly and easily. In tests, a .BIG file is blazingly fast when transferring ultra-large data sets – transferring in minutes, data that took hours or days in other formats.
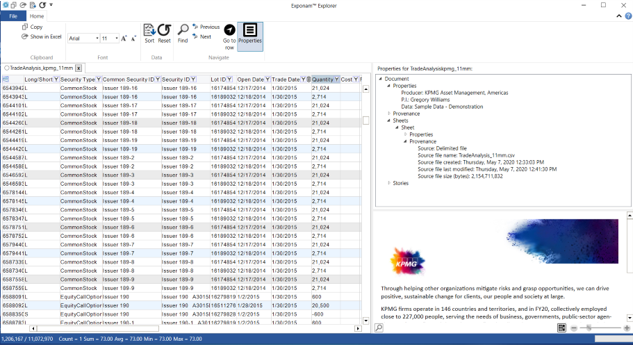 Once files have been distributed and shared, we need an easy way to access and explore data. With the Exponam Explorer, a user can instantly open, filter, sort, and find data from within a .BIG file.
Once files have been distributed and shared, we need an easy way to access and explore data. With the Exponam Explorer, a user can instantly open, filter, sort, and find data from within a .BIG file.
It is easy to explore data of any size – hundreds of rows or millions of rows – making this a great solution when data won’t fit in an Excel spreadsheet.
Users no longer need to spend hours migrating data to databases and writing queries – data is available instantly in a spreadsheet. Alternately, users can query .BIG files directly via JDBC – with the query performance of a database.
Quickly transferring and accessing data aren’t the only data problems.
The world has a major problem with data security. We are constantly learning about yet another company which experienced a major data breach. Not only is data stolen from databases, it is stolen from data files extracted from databases. Extracted data files are not secure. And they are everywhere.
So we made .BIG files fully secure – exceeding today’s security demands around information. And they stay secure. You never decrypt/decompress .BIG like with other compression options. Exponam .BIG files are secure at rest, in process, and in transit.
Data files sitting in email, on laptops, and in the cloud are a security risk as long as they exist. A file which was downloaded or shared one day can be compromised years later. Exponam .BIG files can be generated with specified durations for file access – from hours to days or years. Even more, .BIG files can be dynamically controlled – enabling user specific entitlements and access rights.
.BIG files are tamper-proof and their provenance is guaranteed. The publisher is certifiable and both the file properties and data are unalterable.
At Exponam, we evangelize “Empowerment through Data.” We have created the Exponam ExplorerTM, Exponam BuilderTM, and Exponam .BIGTM file format to enable Secure Sharing and Exploring of Data. Learn more. Visit us at www.exponam.com.
In this video we explore how end users access and explore 100s of millions of rows of data. We see how easily users can take data from databases or the cloud and work within MS Excel.

We understand: Downloading millions of rows is hard
The answer is EXPONAM
With Exponam .BIG files, your users can easily download dataset with 100s of millions of rows.
You do the heavy lifting –making data accessible; providing visualizations; uncovering insights. Let us help you provide true user self-service for secure, large data download, sharing and exploration.
Exponam founder, Roger Dunn, walks us through a brief history of computing and data files. He examines the prevalence and deficiencies of CSV files and the reasons for creating the Exponam data solution.