Exponam.Connect Video Series: 1 – Add a Delta Sharing Server
Exponam Launches Delta Sharing Excel Add-in

For Immediate Release
Date: November 28, 2022
Location: AWS re:Invent 2022, Las Vegas
Exponam announced today the limited release of the Exponam.ConnectTM Excel Add-in, an easy-to-use Excel Application which brings Delta data from Databricks (and Spark) directly to end users in Excel.
Exponam.Connect empowers business users with frictionless, no-code access to data for which they are permissioned via Delta Sharing Server(s). Users easily add data sets from company data repositories, from partner companies, and from data sellers and marketplaces.
Delta data is instantly previewable with easy controls to: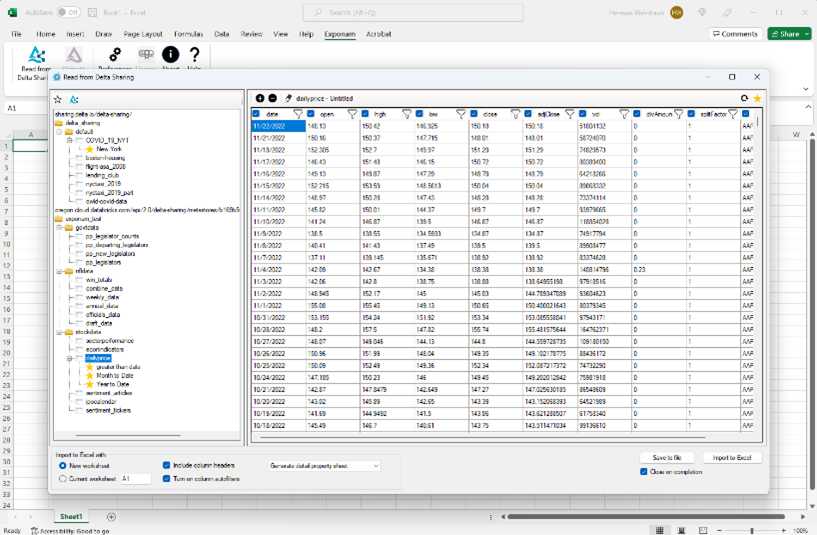
- Filter and select what data to import into Excel
- Save filters for easy repeated actions (e.g. pulling daily, weekly or monthly sales data)
- Write data straight to csv or .BIG files
Roger Dunn, Co-founder and CTO of Exponam, said: “Since 2017, Exponam’s mission has been to make modern data sets accessible to everyone. Reporting and analytics tools are great, but business users want to work with data in a spreadsheet. By partnering with Databricks, our Exponam.Connect product brings data from the world’s leading Lakehouse platform directly to non-technical business users in Excel.”
Herman Weintraub, Co-founder and CEO of Exponam, said: “For the world’s 50 million developers, cloud data and distributed compute platforms like Spark have made data more accessible and better governed than ever. But for the world’s billions of Excel users, access to data has never been more of a challenge. Exponam.Connect, opens cloud data to the world. And with our .BIGTM format, we make modern data easy to securely share, distribute, store and access.”
About Exponam
Exponam evangelizes “Empowerment through Data.” We create better ways to share, move, store, and explore data. Organizations can use Exponam.Connect and .BIG file technologies with their existing systems to make large and sensitive data easier to access, faster to share, and cheaper to store.
CIOReview names Exponam Most Promising Big Data Solution 2022
20 October 2022
For Immediate Release:

A Data Story: An Exponam Origin Tale
Data moves. A lot.

Intra-company. Inter-company. For analysis. For distribution and sale. For teams working from home. For partners, vendors, regulators. To the cloud. From the cloud.
Downloading, moving, and uploading data is slow. Firms address inefficient data movement in two ways:
- By centralizing data in the cloud and providing pointers with access rather than moving the data. For use cases in which data is not needed in other locations, this is a good solution.
- By working to improve bandwidth, limit packet loss, reduce distances – all to speed data transmission. Yet even when transmission is optimized, time to extract and import data is a constraint.
Exponam Origins
Unsatisfied with current solutions to speed data sharing and distribution, we sought a new approach. Rather than addressing the issue of time to move a single bit of data, we focused on the data itself. What could we do to decrease the size of the package, and make it more efficient for extract and import?
Today, data is transferred in different formats – csv, json, xml – but these formats all suffer the same fundamental flaws of being large and inefficient for extract and import. These formats have been used for generations – from a time when data sets were much smaller. From a time when a few million rows was a tremendous amount of data.
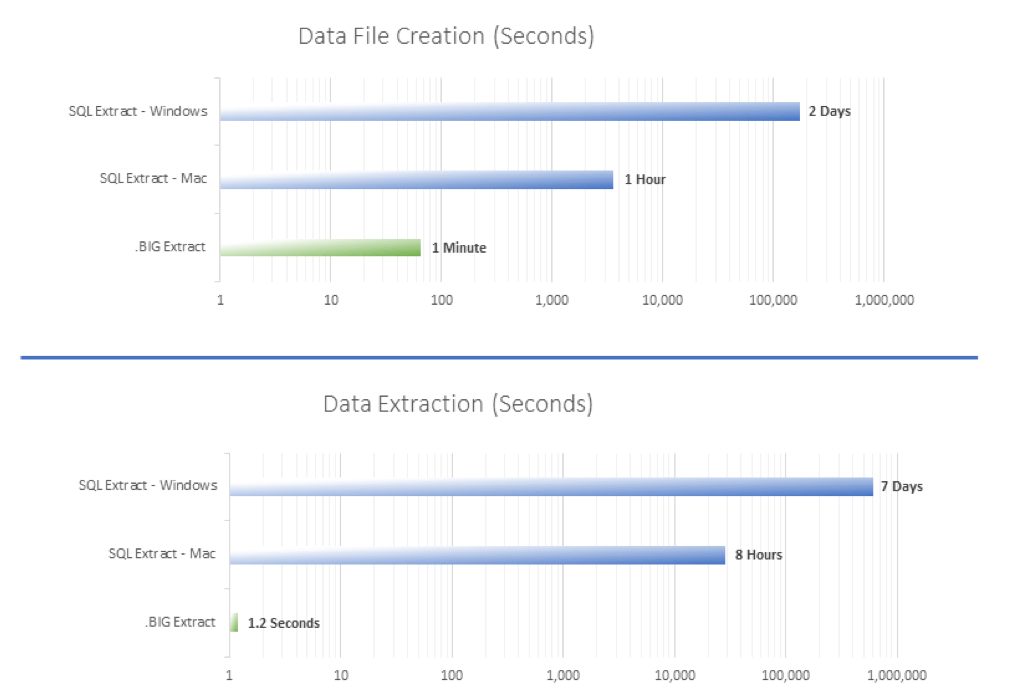 Exponam .BIG
Exponam .BIG
At Exponam, we have created a new data file type – tailor made for today’s data sets. Our data file, a .BIG file, is highly compressed and is optimized for efficient extract and import. It can be used to transport, share, and explore hundreds of millions of rows quickly and easily. In tests, a .BIG file is blazingly fast when transferring ultra-large data sets – transferring in minutes, data that took hours or days in other formats.
Accessing Data
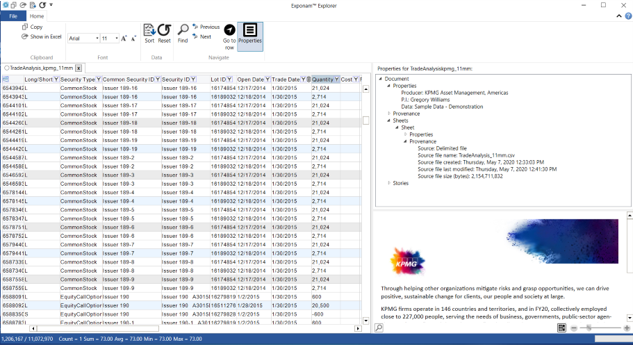 Once files have been distributed and shared, we need an easy way to access and explore data. With the Exponam Explorer, a user can instantly open, filter, sort, and find data from within a .BIG file.
Once files have been distributed and shared, we need an easy way to access and explore data. With the Exponam Explorer, a user can instantly open, filter, sort, and find data from within a .BIG file.
It is easy to explore data of any size – hundreds of rows or millions of rows – making this a great solution when data won’t fit in an Excel spreadsheet.
Users no longer need to spend hours migrating data to databases and writing queries – data is available instantly in a spreadsheet. Alternately, users can query .BIG files directly via JDBC – with the query performance of a database.
Data Security
Quickly transferring and accessing data aren’t the only data problems.
The world has a major problem with data security. We are constantly learning about yet another company which experienced a major data breach. Not only is data stolen from databases, it is stolen from data files extracted from databases. Extracted data files are not secure. And they are everywhere.
So we made .BIG files fully secure – exceeding today’s security demands around information. And they stay secure. You never decrypt/decompress .BIG like with other compression options. Exponam .BIG files are secure at rest, in process, and in transit.
Data files sitting in email, on laptops, and in the cloud are a security risk as long as they exist. A file which was downloaded or shared one day can be compromised years later. Exponam .BIG files can be generated with specified durations for file access – from hours to days or years. Even more, .BIG files can be dynamically controlled – enabling user specific entitlements and access rights.
.BIG files are tamper-proof and their provenance is guaranteed. The publisher is certifiable and both the file properties and data are unalterable.
About Us
At Exponam, we evangelize “Empowerment through Data.” We have created the Exponam ExplorerTM, Exponam BuilderTM, and Exponam .BIGTM file format to enable Secure Sharing and Exploring of Data. Learn more. Visit us at www.exponam.com.
Exponam Video Series #2
In this video we explore how end users access and explore 100s of millions of rows of data. We see how easily users can take data from databases or the cloud and work within MS Excel.
The Myth of Analytics Self Service

THE BIGGEST LIE ANALYTICS VENDORS TELL:
Our users do their analysis within our platform
FACT:
Users download data – To send to external parties; for further analysis; to upload elsewhere. AND YOU provide the ability to download CSVs. But when faced with downloading more than a few thousand rows of data, you offer no solution. “User self-service” becomes “ask IT.”
We understand: Downloading millions of rows is hard
- Too large for a CSV
- Can’t open the file in Excel or Sheets
- Corporate security concerns
The answer is EXPONAM
With Exponam .BIG files, your users can easily download dataset with 100s of millions of rows.
- Download .BIG files as easily as downloading CSVs
- Access millions of rows instantly in a spreadsheet
- Easily filter and sort data
- One click push to Excel
- Fully secure data
- Ultra-compressed
- Files are immutable, provenance and lineage are tracked
- Files are stamped with originating system details – extending your reach to all who interact with the files
You do the heavy lifting –making data accessible; providing visualizations; uncovering insights. Let us help you provide true user self-service for secure, large data download, sharing and exploration.
The Great Myth of Data Security
MYTH: Perimeter & Endpoint Security Protects Your Data
FACT: Your Data Will Get Out
You protect your data repository.
You protect your network.
You provide users with visualizations, summaries, and exception analysis.
Yet, thousands of data files are extracted and downloaded from your repository. These CSV and XLS files reside on your network drives, on employee machines, in the public cloud, and in employees’ email. These data files are the most vulnerable point of attack for malicious actors.
If you are not securing data files, you are not protecting your data.
Current State of Data Security:
Data security in 2019 is achieved through a series of concentric security perimeters which attempt to ensure that access to data is authorized. We secure network and application endpoints. We secure, manage, monitor, and audit access to databases. We attempt to scan and block content from leaving our perimeter.
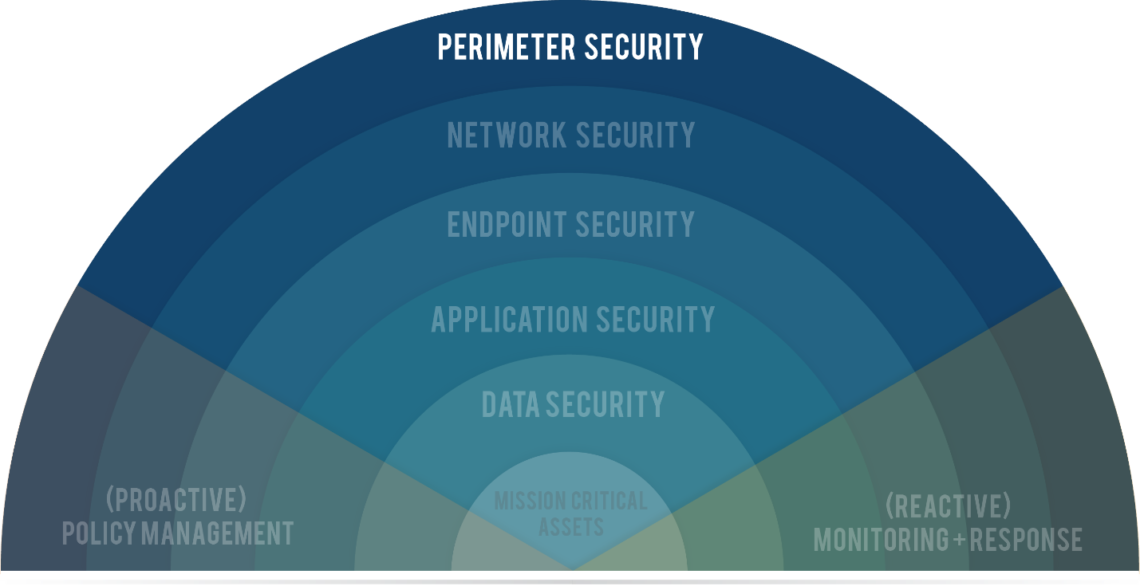
But data gets out. It gets out intentionally when we distribute to partners, vendors, clients. It gets out for legitimate reasons when managers and analysts drill into the data. It gets out when we are hacked or otherwise compromised.
We have thousands of data files that are extracts from our databases. They exist as CSV files, as XLS files, and other delimited file types. They reside on our network drives, on employee machines, in the public cloud, and in employees’ email. These files are all potential security concerns.
We address this massive security concern through training employees on corporate data policies. We instruct how data should be handled, where should it be sent and with whom should it be trusted.
THIS IS INSANE.
The Exponam .BIG Solution:
Exponam .BIG files are an easy to use alternative to downloaded CSV files. .BIG files are fully encrypted, ensuring that data files are completely secure anywhere they reside, at rest, in use, and in transit. Access is controlled via passphrase, token, or multifactor authentication. Dynamic entitlement is available for further control of sensitive GDPR or HIPAA governed data.
Your data is secure anywhere it resides – at rest, in use, and in transit.
.BIG files are highly compressed, enabling easy download, distribution, and sharing – no matter how many rows of data (thousands, millions, 100s of millions of rows).
.BIG files are easily accessed via a spreadsheet viewer for instant filtering, sorting, and finding data. Isolated subsets are moved to excel with a single click. .BIG data is also accessed via JDBC, Java and Windows libraries.
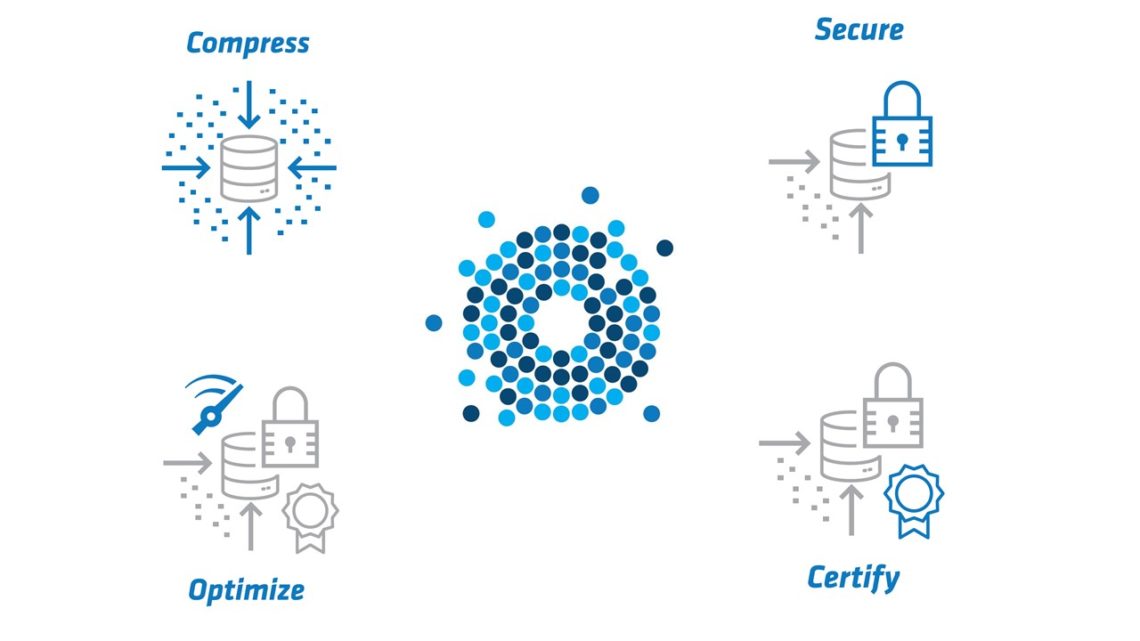
.BIG files are completely tamper-proof and their provenance is guaranteed. You can be confident that the publisher is genuine, the file properties are accurate, and the data is unaltered.
It is time to learn more. Contact us for trial information.